RNNs Part Two
Apr 30, 2014
Some more RNN attempts
Building on Jung-Hyung’s encouraging results, I tried going smaller and training an RNN to overfit a single phone.
I implemented gradient clipping (my version rescales the gradient norm when it exceeds a certain threshold) and tried increasing the depth of the hidden-to-hidden transition, as suggested in Razvan’s paper.
The resulting model has the following properties:
- Input consists of the 240 previous acoustic samples
- Hidden state has 100 dimensions
- Input-to-hidden function is linear
- Hidden-to-hidden transition is a 3-layer convolutional network (two convolutional rectified linear layers and a linear layer)
- Hidden non-linearity is the hyperbolic tangent
- Hidden-to-output function is linear
It was trained to predict the next acoustic sample given a ground truth of 240 previous samples on a single ‘aa’ phone for 250 epochs, yielding an MSE of 0.009.
Here are the audio files:
Original:
Ground-truth-based reconstruction:
Prediction-based reconstruction:
And here’s a visual representation of the files (red is the original, blue is using ground truth and green is the prediction-based reconstruction):
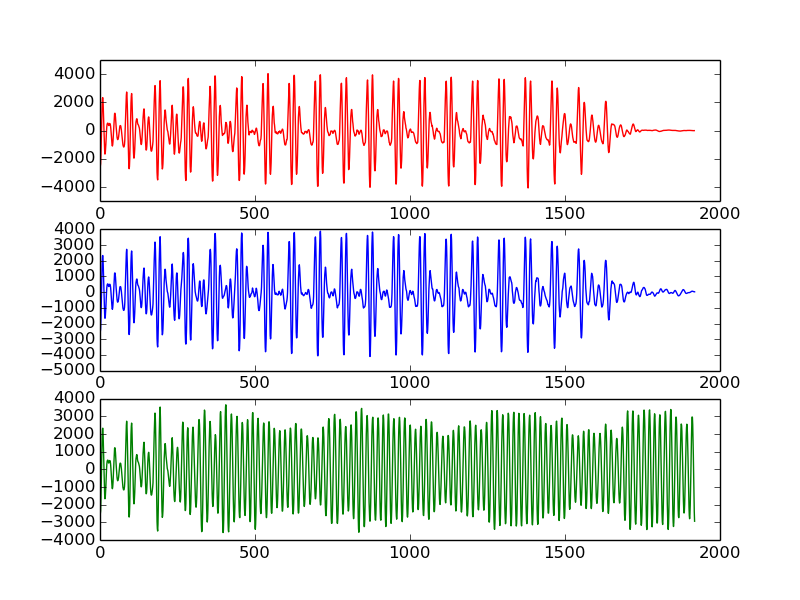
Unfortunately, as you can see (and hear), it’s not on par yet with Jung-Hyung’s results, even with the extensions to the original model.
Share